{kind=link}
{kind=link}
{kind=link}
Project information
- Category: Responsible AI / Data Science
- Project duration: Jan '25 - Mar '25
- Team size: 3
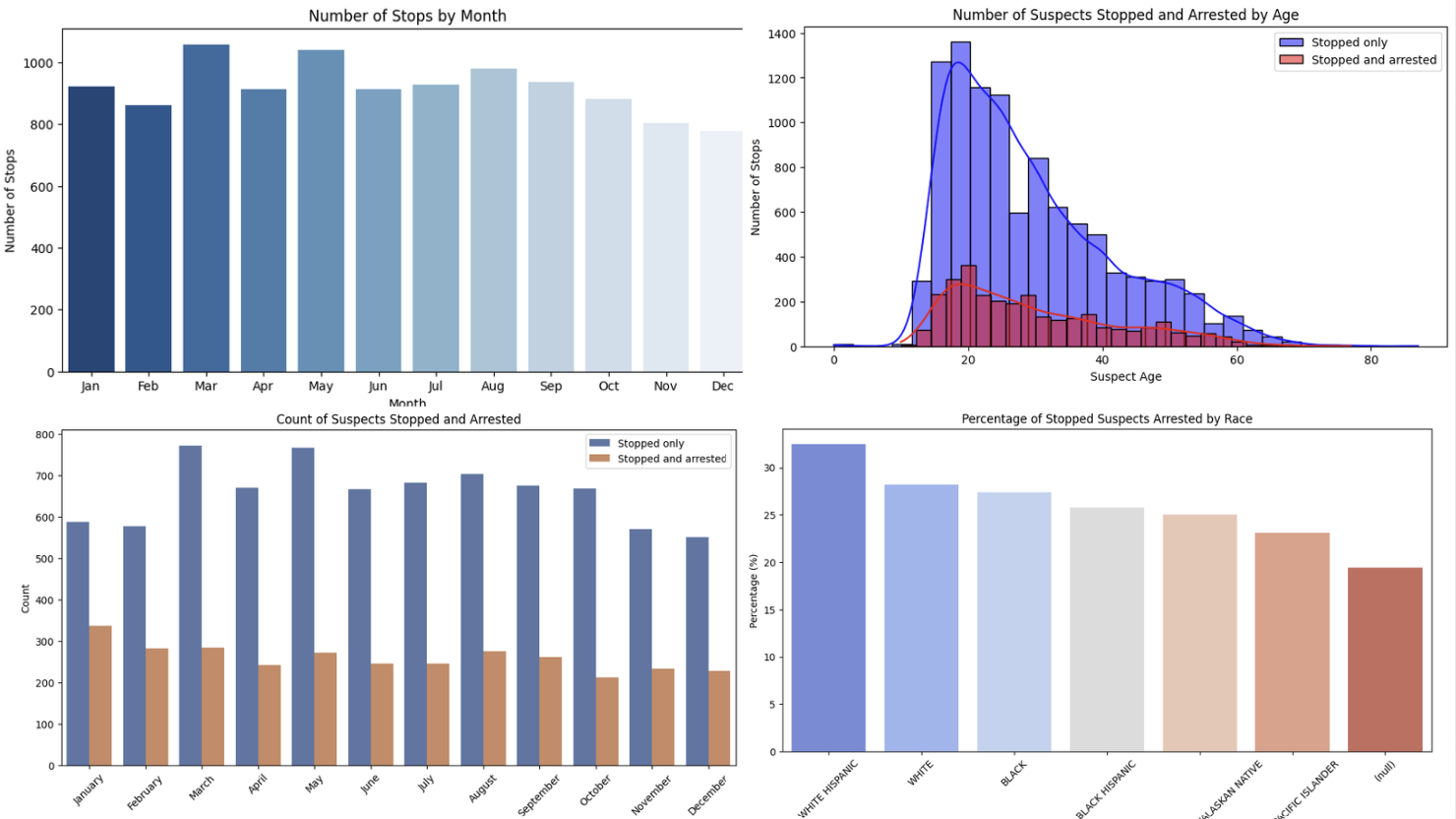
- Dataset: NYPD Stop-Question-and-Frisk (2003-2024)
- Github URL: Stop-and-Frisk Bias Analysis
- Video Presentation URL: Video URL
Freeze! Is This Model Fair?
Technology(s) Used: Scikit-learn, Fairness Indicators, Platt Scaling, Random Forest, AdaBoost, Python
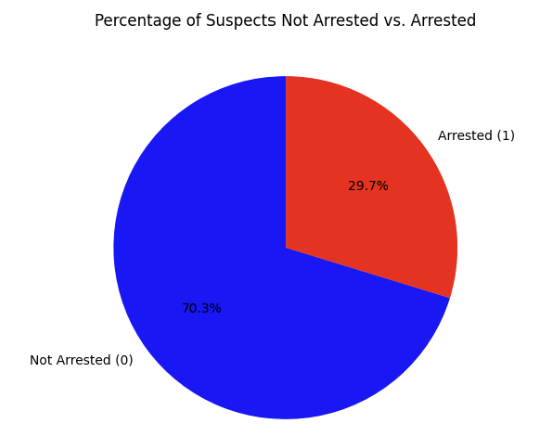
- Objective: Analyzed over two decades of NYPD stop-and-frisk data to detect and mitigate predictive bias in arrest outcomes across sensitive demographics (race, gender, and age).
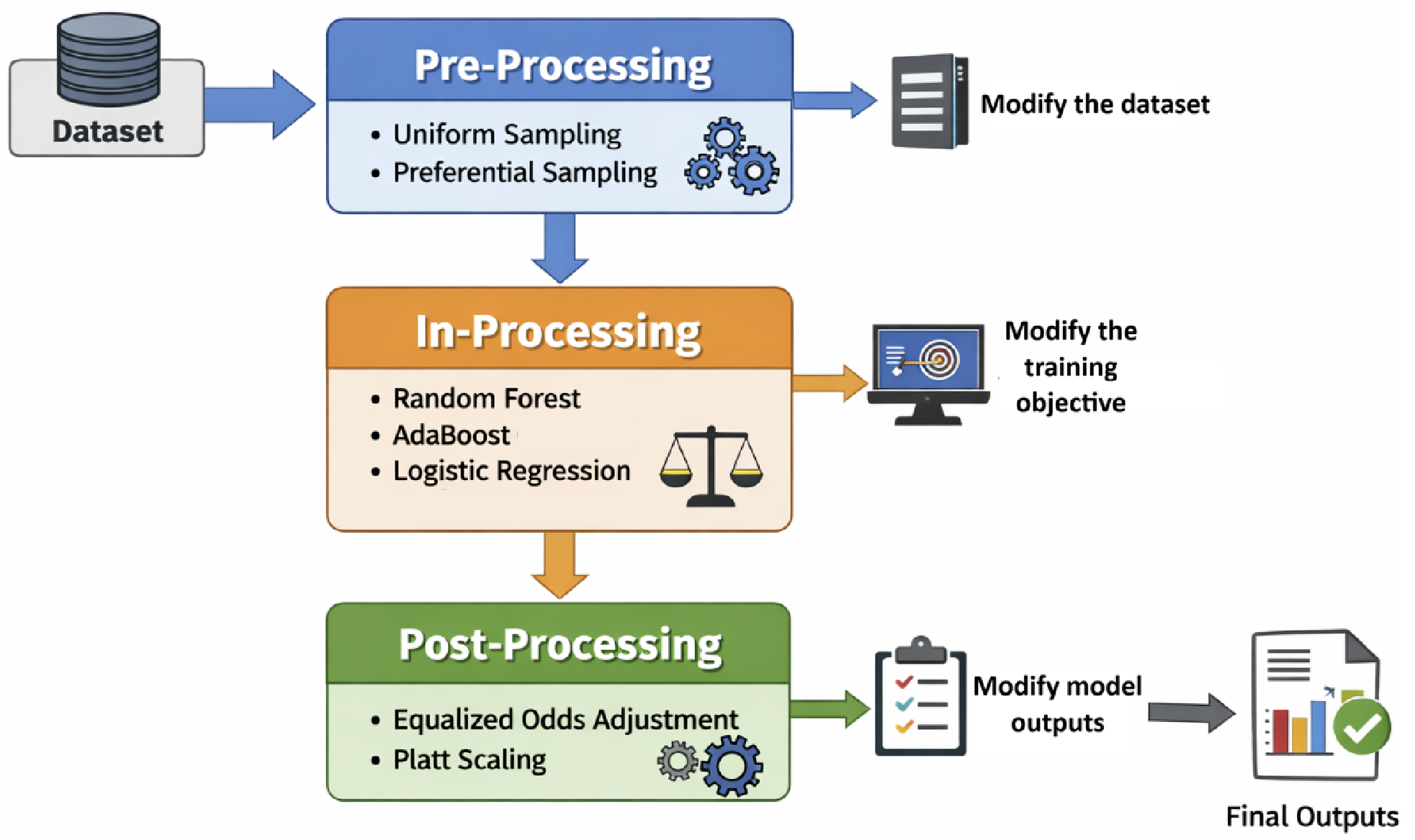
- Fairness Interventions: Implemented a three-stage fairness pipeline, applying pre-processing techniques such as uniform sampling and preferential sampling to mitigate dataset bias, and post-processing methods including Platt scaling to adjust predictions and enforce equalized odds after model training.
- Modeling: Built robust classifiers using in-processing strategies, training Logistic Regression, Random Forest, and AdaBoost models, and assessed performance using balanced accuracy and demographic parity metrics.
- Results: The post-processing + Random Forest pipeline emerged as the best performer, increasing balanced accuracy from 0.68 to 0.71 while achieving significantly more equitable TPR/FPR across groups.