{kind=link}
{kind=link}
{kind=link}
{kind=link}
Project information
- Category: Machine Learning / Healthcare Analytics
- Project duration: Sep '24 - Dec '24
- Team size: 3
- Dataset: CDC Diabetes Health Indicators (253,680 samples)
- Report URL: Detailed Report
Diabetes Risk Prediction
Technology(s) Used: Python, Scikit-learn, Pandas, GridSearchCV, Random Forest, SVM
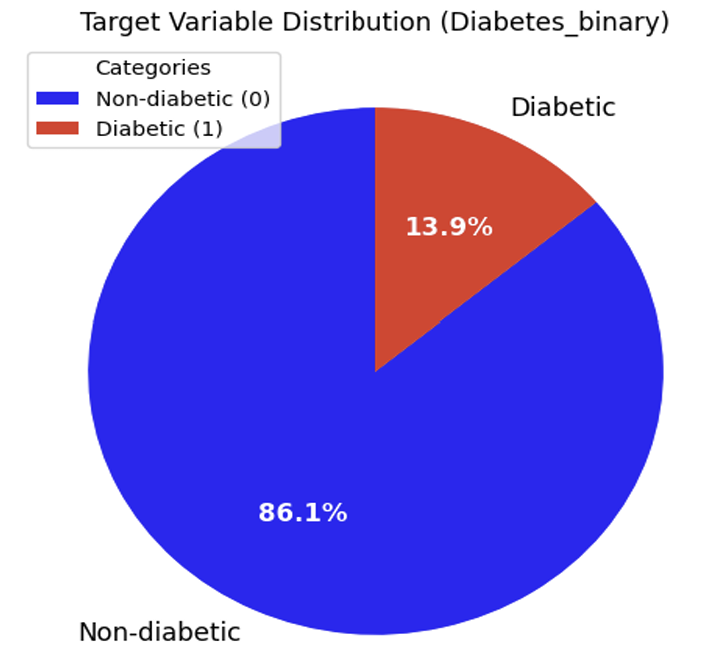
- Data Engineering: Cleaned and processed the massive CDC Diabetes Health Indicators dataset. Addressed significant class imbalance using oversampling techniques to ensure the minority (diabetes/prediabetes) class was properly represented.
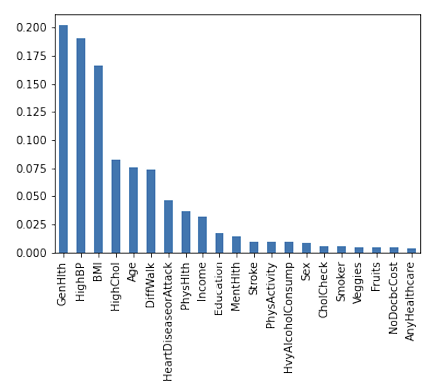
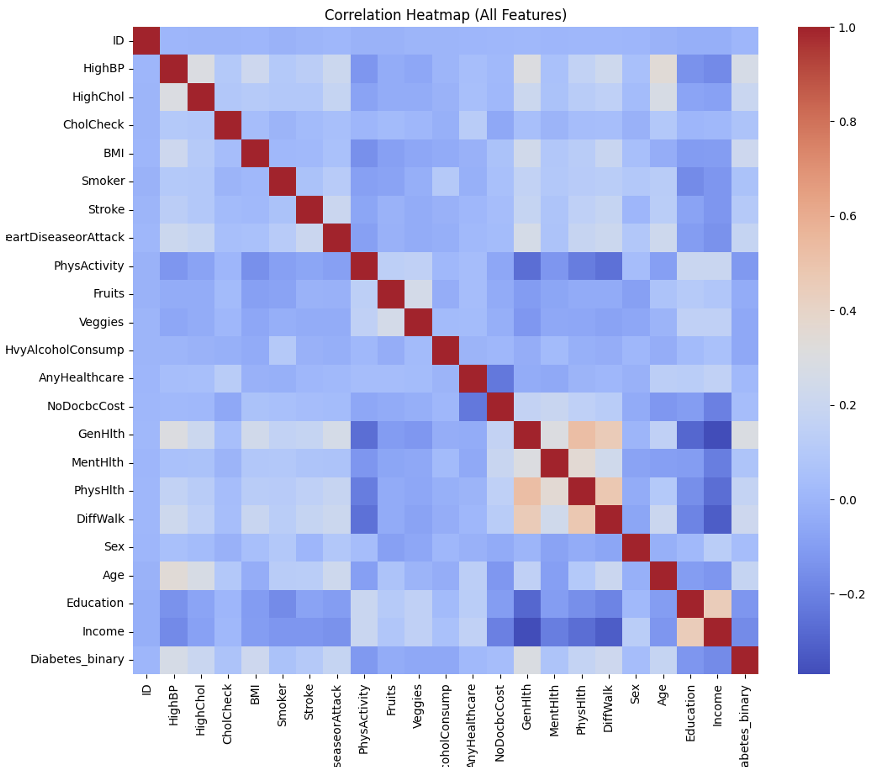
- Feature Selection: Conducted multi-collinearity analysis and used Random Forest Gini importance to distill 21 variables down to 7 key health indicators, optimizing model efficiency.
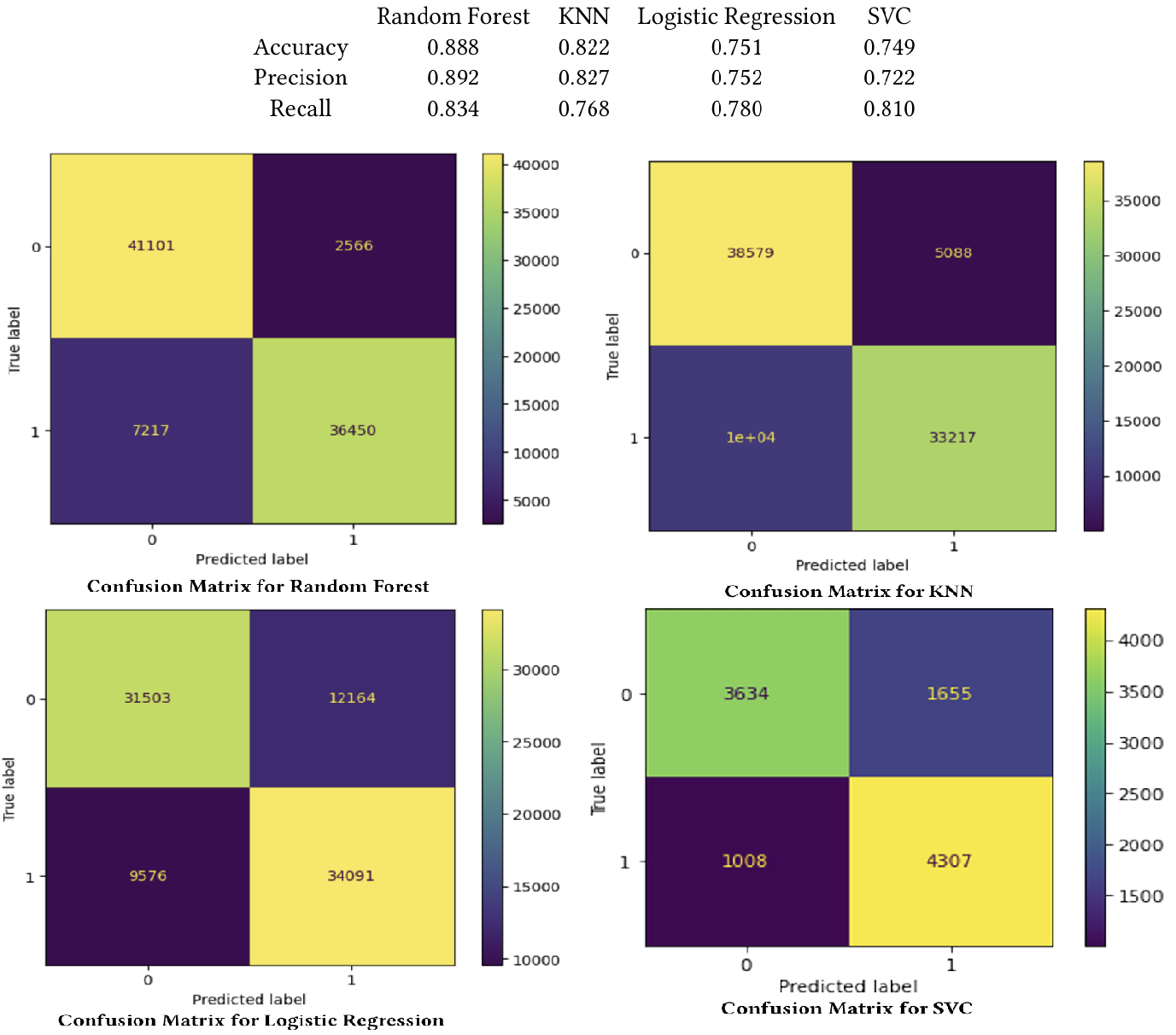
- Model Development: Implemented and compared Logistic Regression, SVM, Random Forest, and KNN. Utilized GridSearchCV for hyperparameter tuning and cross-validation to prevent overfitting.
- Performance: Achieved an 88.79% accuracy and 89.24% precision. The model provides a reliable framework for early screening based on behavioral and health metrics.